La programación concurrente es el futuro inmediato (o debería serlo)

Sistemas concurrentes asícronos
Durante las últimas décadas, los equipos informáticos han progresado cómodamente debido al crecimiento exponencial de la capacidad sin merma significante en el modelo de cálculo subyacente. El hardware siguió durante años la Ley de Moore, las velocidades de reloj se incrementaron, y el software se escribía para explotar este crecimiento incesante en el rendimiento, a menudo por delante de la curva de los equipos físicos. Esa relación simbiótica entre hardware y software continuó sin cesar hasta hace muy poco. La Ley de Moore sigue vigente, pero se ha obviado la ley no escrita que dice que las velocidades de reloj seguirán aumentando proporcionalmente… ¡siempre!
Las razones de este cambio de dirección de hardware se pueden resumir en una sencilla ecuación formulada por David Patterson, profesor de Ciencias de la Computación en la Universidad de California, en Berkeley:
Pared de energía + Pared de memoria + Pared ILP = Una pared de ladrillos para el rendimiento en serie
La disipación de calor y energía en la CPU aumenta proporcionalmente a la frecuencia de ciclos de reloj, imponiéndose un límite práctico en las velocidades de reloj. Además, hoy en día, la capacidad de disipar el calor ha alcanzado ya un límite físico. Como resultado de ello, un significativo aumento en la velocidad de reloj sin una refrigeración exagerada, y muy cara, o sin nuevos materiales y avances tecnológicos, es simplemente imposible. Esto se refiere a la parte de «Pared de energía» (Power Wall) en la ecuación
Por otro lado, las mejoras en el rendimiento de la memoria se quedan cada vez más por detrás de la productividad del procesador, haciendo que el número de ciclos necesario de la CPU para acceder a la memoria principal no pare de crecer continuamente. Esto es lo que se conoce como «Pared de memoria» (Memory Wall).
Por último, los ingenieros de hardware han mejorado el rendimiento del software secuencial haciendo que las instrucciones se ejecuten antes de que se conozcan los resultados de las instrucciones anteriores, una técnica conocida como Paralelismo a nivel de instrucción (ILP son sus siglas en inglés). Las novedades en ILP son difíciles de predecir, y su complejidad aumenta el consumo de energía. Como resultado de ello, las mejoras en ILP también se han estancado, lo que resulta en la llamada «Pared ILP» (Wall ILP).
Conclusión de la ecuación: todo esto es como dar contra un muro. Hemos llegado, pues, a un punto de inflexión. El ecosistema de software debe evolucionar para apoyar mejor y adaptarse correctamente a los sistemas de varios núcleos, y esta evolución llevará tiempo. Para beneficiarse de la rápida mejora en el rendimiento de los equipos y para mantener el paradigma de «una vez escrito, deberá ejecutarse cada vez más rápido en cada nuevo hardware» (write once, run faster on new hardware), la comunidad de desarrolladores debemos aprender a construir aplicaciones simultáneas multihilo. Una mayor y más amplia adopción de la concurrencia también habilitará al binomio Software + Servicios para modelos asíncronos y sistemas de acoplamiento flexible (loose coupling), para desarrollo en paralelo del lado del cliente y, también, para computación en la nube, o cloud computing, del lado del servidor.
Las plataformas del tipo Windows o .NET Framework, por ejemplo, ofrecen compatibilidad total para concurrencia. Este apoyo ha sido desarrollado desde hace ya más de una década, desde la introducción del soporte multiprocesador en Windows NT. Posteriormente, se han sucedido mejoras en el rendimiento de la programación de subprocesos, sincronización de las API y jerarquía de la memoria. Ello ha hecho de los sistemas Windows (y de otros entornos también) unas herramientas perfectas para la maximización de la simultaneidad.
Por lo tanto, debemos aprender cuándo utilizar estructuras de desarrollo multihilo en nuestras aplicaciones y que la importancia de la arquitectura y el diseño limpio es fundamental para la reducción de la complejidad del software, y mejora la capacidad y facilidad de mantenerlo. Hay que poner énfasis en la comprensión, no sólo de las capacidades de la plataforma, sino también de las mejores prácticas emergentes.
Programar una aplicación Facebook para torpes en cinco minutos

Desarrollo para Facebook
Cuando «alojamos» una aplicación en Facebook, realmente no la estamos alojando allí, sino que estamos utilizando Facebook como un proxy entre nuestra aplicación y los usuarios de la red social. Una aplicación típica basada en Facebook funciona de la siguiente manera:
- Los usuarios acceden a
http://apps.facebook.com/nombre_de_nuestra_aplicacion. - Facebook hace una llamada a nuestros servidores, esto es, donde tenemos alojada la aplicación, a través de una etiqueta
iFramede HTML. - Los servidores reciben la llamada y formatean los datos que van a enviar acorde a la petición. Durante este tiempo, estos servidores donde alojamos la aplicación pueden devolver llamadas al API de Facebook para solicitar información adicional (amigos, información del perfil, etcétera) antes de mandar los datos al usuario.
- Entonces, nuestras máquinas devuelven a Facebook los datos formateados a través de un
iFrame, a modo de marco dentro de la red social - Facebook parsea (lee y comprueba) esos datos y los formatea más a fondo, añadiendo su encabezado, columna lateral y demás.
- Por fin, Facebook envía la página completa al usuario.
Es un proceso sencillo y lógico, como se puede comprobar. Elegir un lenguaje de programación y un entorno de desarrollo va en función de nuestras pretensiones, gustos o limitaciones. Al final es desarrollo web puro y duro, sin más. Existe un Facebook Javascript SDK que es, sin lugar a dudas, la librería de código abierto (open source) más fácil de utilizar. Hay también un Facebook PHP SDK, un Facebook Python SDK y hasta kits de desarrollo oficiales para iOS y Android. También existen entornos no oficiales en Ruby, Perl, Java e, incluso, en .Net. Por supuesto, también se puede utilizar programación web a pelo en HTML, JavaScript, Java, PHP, ASP o lo que sea. Al fin y al cabo, el resultado ha de ser una web embebida.
Por lo tanto, desarrollar una aplicación para Facebook se podría resumir en cuatro simples pasos: el primero es elegir un editor para escribir el código; el segundo, decidirse por un hosting o alojamiento web que sirva nuestras páginas; tercero, un lenguaje de programación y, si lo prefieres, un entorno de desarrollo; y, el cuarto y último, instalar la aplicación de extensiones de desarrollador, lo que llaman Facebook Developer Application (algo que se hace en dos clics desde la web de Facebook).
Una vez que tengamos acceso a las herramientas de desarrollo de Facebook, es necesario contar con cierta información básica acerca de la aplicación que se va a desarrollar. Como mínimo, debemos saber cómo llamar a su instancia y dónde alojarla. De esta manera, Facebook puede ofrecer a los usuarios la dirección correcta cuando quieran visitar nuestra aplicación. A su vez, Facebook nos aportará información que se puede utilizar para construir la aplicación, como por ejemplo el ID de la aplicación y, en función del tipo, una clave secreta de su API.
Para todo ello necesitamos dirigirnos a http://www.facebook.com/developers y hacer login con nuestros datos de la red social. Si nos lo pregunta, deberemos hacer clic en el botón Permitir, para que Facebook acceda a la información de nuestra cuenta. Y ya está, ahora ya tenemos asociada la aplicación de desarrolladores a nuestra cuenta en Facebook. El siguiente paso es crear nuestra aplicación, y lo vamos a hacer en sólo cinco minutos. Sí, sí; sólo cinco minutos.
Minuto 1. Configurar la aplicación. En la web del desarrollador hacemos clic en App y luego en Crear una nueva aplicación. Escribimos el nombre de la aplicación (le llamamos teknoPrueba), el espacio de nombres (el nombre de nuestra aplicación para la URL en Facebook; que no debe existir ya, por cierto; le ponemos teknoprueba) y seleccionamos categoría y subcategoría. Escribimos el captcha y listo. En la opciones bajo el epígrafe App on Facebook escribimos la URL real del alojamiento de la aplicación, por ejemplo https://www.teknoplof.com/teknoAPP/ (importante la barra inclinada del final). Guardamos los cambios.
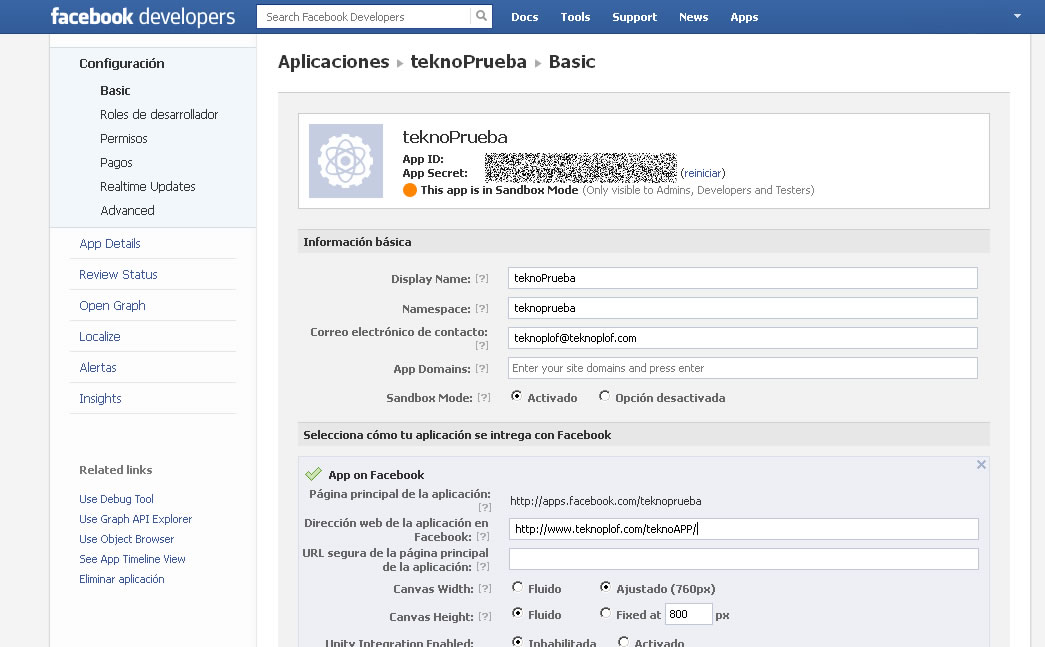
Configuración (clic para agrandar)
Minuto 2 a minuto 4. Programar la aplicación. Dos minutos son más que suficientes para generar un HTML sencillito. Pensemos que, como ya hemos aclarado, una aplicación de Facebook no es más que una web que se muestra encima de la de Facebook a través de un marco del tipo iFrame. Podemos generar una web sencillita y, también, podemos complicarnos la vida de la manera más perversamente intrincada (mostrar nombre y foto de perfil del usuario que entra, actualizar su muro, guardar datos asociados y un largo etcétera). Para aprender sobre todo ello tenemos la posibilidad de recurrir a los documentos en línea para desarrolladores, desde donde podremos obtener información muy valiosa sobre las distintas API de Facebook, los plugin, los SDK y demás.
Minuto 5. Ver y comprobar la aplicación. En nuestro ejemplo accederíamos a http://apps.facebook.com/teknoprueba y, si todo va bien, podremos ver la web diseñada totalmente embebida en Facebook.
Ya está, ya hemos creado nuestra primera aplicación para Facebook. ¿Fácil, verdad? Pues a practicar se ha dicho.
En la serie ‘El barco’ usan el HTML de la web de Google como protocolo antiincendios

‘El barco’ la vuelve a liar
Desde el punto de vista técnico y tecnológico, la serie cojea más que una mesa de Ikea. Ya comentamos en su momento lo cutre y salchichero de sus efectos digitales en 3D, algo que, si bien ha mejorado un poquito con el tiempo, todavía no alcanza la calidad visual de otras producciones con el mismo nivel de presupuesto. Pero ahora he descubierto otra joya, un dechado de perfección técnica informática al más puro estilo peliculón vespertino tragicomédico y soporífero de Antena 3. Algo que, quizás quisieron hacer pasar desapercibido o, quizás, quisieron incluir a guisa de huevo de pascua para que los frikis gafotas lo encontráramos. Esto último lo dudo bastante.
En el capítulo 9 de la tercera temporada (lo que vienen a llamar los geeks el 3x09), Gamboa, el malo malísimo de la película, encierra al curilla Palomares en la sala de máquinas y hace saltar la alarma de incendios. Esto provoca que se ponga en funcionamiento un sistema antiincendios del buque escuela que extrae el oxígeno del compartimento y libera CO2 a través de una tubería, con el fin de sofocar las llamas por ahogamiento. El problema es que el personaje de Andrés Palomares se encuentra allí sin poder salir y a punto de perder la vida asfixiado.
Desde el puente de mando, el capitán, el primer oficial y la doctora Julia contemplan desalentados cómo van subiendo los niveles de dióxido de carbono hasta puntos muy peligrosos para el muchacho, mientras hablan con él por walkie-talkie. El protocolo contra incendios ha activado una aplicación informática en el ordenador del puesto del capitán, una preciosa pantalla de Windows (imagen siguiente), con su barra de herramientas y sus botoncitos de Nuevo, Guardar, Buscar, Ayuda, Rehacer y Deshacer (entre otros), tan imprescindibles en este tipo de software de seguridad. Además, la pantalla está dividida en varias áreas, tituladas como Status, Items, LogBoot, Process y Avanced, cada una con sus alarmas, sus controles, sus configuraciones etcétera.

Pantalla de control (clic para aumentar)
Si nos centramos en las dos áreas verticales de la izquierda (LogBoot y Process) podemos observar que, lo que sea que esté haciendo toda la parafernalia antiincendios produce un listado continuo de códigos en ambos cuadros, a modo de depuración, compilación o ejecución de órdenes supercomplejas, supercomplicadas, superemocionantes de la muerte, comandos megaprofesionales no comprensibles por los seres humanos llanos y sólo alcanzables al entendimiento de los profesionales de la informática especializada en la seguridad integral de los navíos modernos más avanzados. Pues no, oiga, es código HTML muy rápido para que no se distinga en tiempo de visualización normal del capítulo. ¡Y qué código HTML! (Véase foto subsiguiente y ábranse bien los ojos).
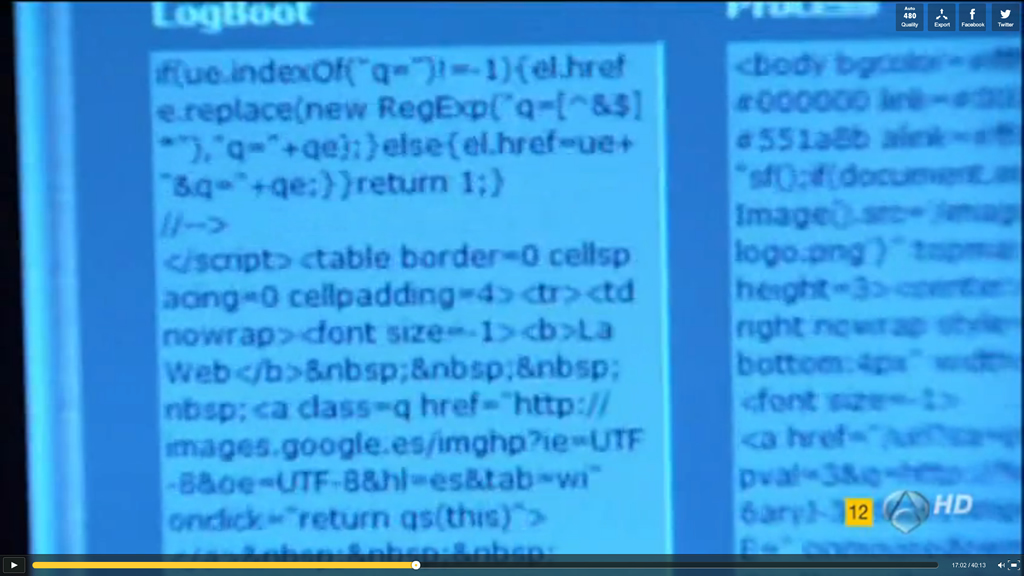
Código HTML en pantalla (clic para aumentar)
El HTML (con su javascript, su CSS y demás) no es otro que el código interno de la web del motor de búsqueda de Google España; efectivamente, el HTML de www.google.es (en aquel momento, claro). En determinado instante del visionado, hay una oportunidad en la que se aprecia bien (en modo pausa) la pantalla del equipo y, durante cuatro o cinco fotogramas, se pueden distinguir perfectamente las etiquetas, los valores, los parámetros y hasta textos reconocibles mundialmente como el «Voy a tener suerte» del botón de la página del buscador. Increíble, pero cierto. (Imagen a continuación).
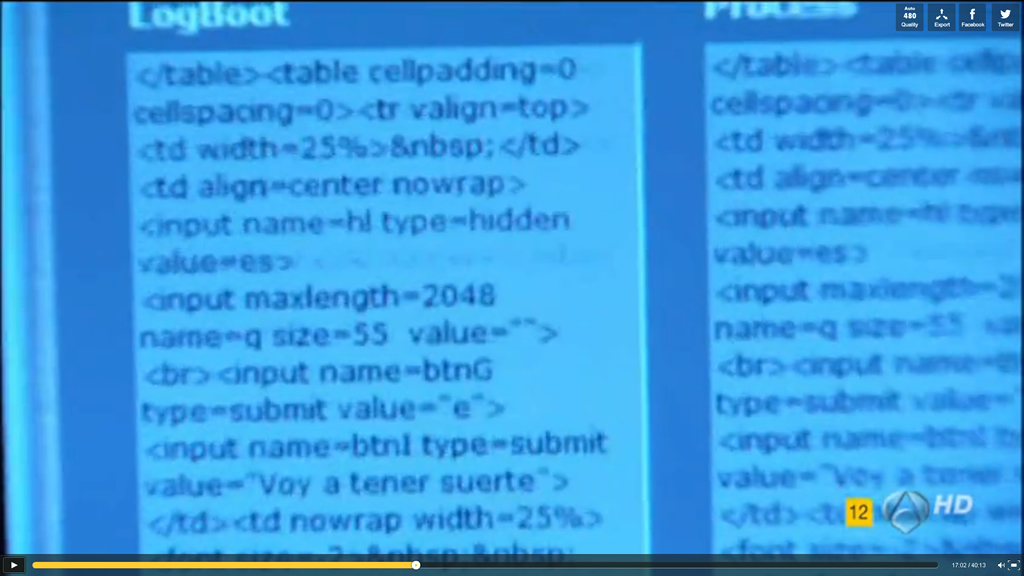
HTML de un botón de Google (clic para aumentar)
En otro punto del código aparece la palabra Origami entre etiquetas <title> de título, algo que me desconcertó hasta que recordé que la gran G homenajeó con uno de sus doodle a Akira Yoshizawa, el maestro japonés que elevó el origami a la categoría de arte. Este doodle apareció allá por marzo de 2012, y el capítulo nueve de la temporada tres de ‘El barco’ se grabaría más o menos por esas fechas; porque esta tercera de las temporadas se estrenó en octubre del mismo año 2012. (Imagen siguiente).

El asunto del origami (clic para aumentar)
Estamos muy acostumbrados a ver aberraciones informáticas y tecnológicas en series y largometrajes; desde direcciones IP que no existen, sistemas operativos que hacen milagros en muchos colorines, correos electrónicos que se abren con alucinantes animaciones e interfaces gráficas imposibles que aumentan mil millones de veces la resolución de una fotografía hecha desde un satélite. Por supuesto, los chicos de ‘El barco’ no nos podían fallar en este asunto y debían meter su propia gamba técnica haciéndonos creer que aquello es más que sofisticado.
Pocos ejemplos hay en el mundo del celuloide del tipo ‘Matrix Reloaded’ y su exploit SSHv1 CRC32, con un manejo de la escena impecable. Es una pena, pero es así. Seguiremos asistiendo a despropósitos informáticos mientras los responsables no se preocupen un poquito de documentarse en condiciones.
Para terminar lo haremos con el vídeo de la escena completa, que comienza, más o menos, en el minuto 16:20.
Los medios no sólo no entienden de tecnología, sino que encima se copian entre ellos los muy cabestros

Borregos al redil
BitTorrent y uTorrent de los filtros antipiratería que contienen sus autocompletados y sus resultados de búsqueda. Esto es, y repito, ELIMINAR dichos términos de SUS FILTROS ANTIPIRATERÍA, o sea, dejar de considerarlos como algo susceptible de ser considerado una violación de los términos del copyright.
Como decían en este blog, hace tiempo, «la batalla de los defensores del copyright contra la llamada (o mal llamada, en muchos casos) piratería llevó a los principales responsables de los motores de búsqueda más importantes de la web a filtrar, parcialmente, algunos resultados de búsquedas relacionados a los entes malvados y demoníacos, como los catalogan asociaciones como la MPAA (Asociación Cinematográfica de Estados Unidos) […]. Por supuesto, términos como BitTorrent, uTorrent, Rapidshare y Megaupload, fueron las principales víctimas de los filtros».
ALT1040 basaba su entrada en otra anterior de TorrentFreak (en inglés), a la cual citaba como fuente. El caso es que me llama poderosamente la atención ver la primicia llegar al agregador de noticias Menéame (era cuestión de minutos), enlazando a un periódico valenciano en línea. Y digo que me llama la atención porque la crónica contaba la noticia totalmente al revés (imagen siguiente). Venía a decir que Google pasaba «a retirar los términos BitTorrent y uTorrent de sus servicios de autocompletado y Google Instant […]. Estos términos han pasado a formar parte de la lista de términos relacionados con la piratería, aunque en un principio la compañía del buscador no los consideró como tal».

Noticia en Levante
¿Mande? ¿Qué demonios estaba ocurriendo aquí? Yo no entendía nada. Retorno a ALT1040 y a TorrentFreak y vuelto a leer la reseña por segunda, tercera, cuarta y quinta vez; por si las moscas, no vaya a ser que tenga yo el día retorcido y no me entere de las evidencias más allá del arco de mis narices. Pues nada, oiga, lo mismo que antes. Me quedo frío.
Empiezo a investigar y compruebo, con estupor, asombro y desconcierto, que la mayor parte (por no decir todos) de los medios digitales españoles están dando la noticia (los que la dan) totalmente tergiversada y deformada; totalmente al revés, vaya. El ABC, El País, La Nueva España, El Imparcial y el anterior diario Levante, entre otros muchos. Esto me lleva a pensar que el borregueo mediocre que caracteriza a la prensa española ha vuelto a surgir de su letargo una vez más.

Noticia en ABC, El País y La Nueva España
Tiro de la manta con intención de llegar a la fuente principal, que sospecho sea una agencia de noticias, y termino en Europa Press, donde ofrecen la noticia igual de mal y cuyo texto tiene un extraño tufillo que me recuerda a los ya leídos anteriormente en los medios. Pero lo más gracioso deprimente del asunto es que desde Europa Press se cita como fuente ¡el mismo post de FusionFreak que se cita en ALT1040! Impresionante.

Noticia y fuente en Europa Press
¿Puede ser una cuestión de falta de cultura tecnológica o es que simplemente en Europa Press no saben inglés? Tanto un asunto como el otro me parecen igual de graves, así que elijan ustedes mismos.
NOTA: Europa Press ha cambiado ya su noticia, de ahí que me apresurara yo a realizar capturas de pantalla en el momento exacto (que me lo veía venir). Los demás medios aún no han reculado. Una retirada a tiempo no siempre es una victoria, pero salva un poquillo la honra.
La serie de juegos de Horacio del ZX Spectrum

Horacio
Programado entre Beam Software (luego Melbourne House) y Psion Software (en España distribuido y traducido por Investrónica) era una burda copia (ahora lo llaman inspiración) del ‘Pac-Man‘ de Namco. Horacio debía coger todas las estrellas de la pantalla para superar el nivel. Unas campanas, a modo de bonus, le permitían zamparse a los enemigos sin miramientos durante unos segundos. Lo dicho, un auténtico clon de Pac-Man.
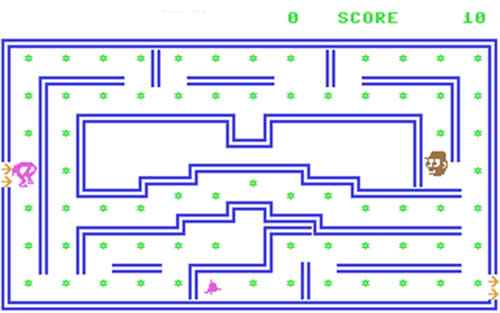
Pantalla de ‘Hungry Horace’
Lo bueno de los juegos de Horacio es que eran «gratis», es decir, solían regalarlos al comprar el aparato, es por ello que son títulos que los que vivieron su infancia en los ochenta recordarán a buen seguro. Psion también se encargó, entre otras cosas, del desarrollo de la cinta ‘Horizons‘ (‘Horizontes’ en España), otro regalo de bienvenida de Sinclair al comprar su «gomas» y que traía títulos inolvidables como ‘El Muro’ (‘Thro’ the Wall‘), un juego tipo breakout, esto es, un machacaladrillos de los de toda la vida, pero que a los spectrumianos nos llenó horas y horas de nuestro tiempo libre.
El segundo de los juegos de la trilogía, también aparecido en 1982, fue ‘Horace goes skiing‘ (‘Horacio esquiador’). Este dechado de tecnología punta estaba dividido en dos fases claramente diferenciadas. En la primera de ellas, Horacio debía cruzar una carretera, esquivando vehículos de todo tipo, para recoger unos esquís. Esta parte del juego recuerda (imita descaradamente) al ‘Frogger‘ de Sega, lo que nos lleva a pensar que no se rompían mucho la cabeza para idear guiones originales. En la segunda de las fases, Horacio caía por una colina nevada y debía sortear los banderines y otros obstáculos hasta llegar a la meta. Y vuelta a empezar, en modo bucle, cada vez más rápido.
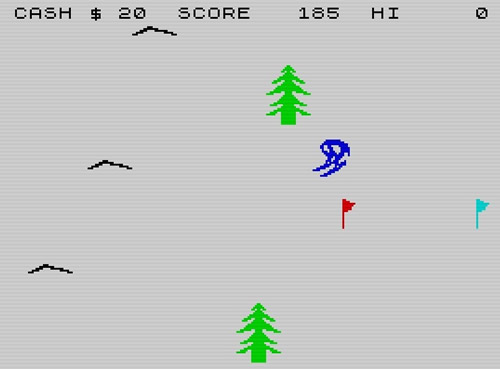
Pantalla de ‘Horace goes skiing’
Los gráficos son impresionantes, el sonido demoledor, el grácil movimiento de subir la adrenalina; el Spectrum daba para mucho más, pero en esta serie no se preocuparon lo más mínimo de sacarle todo su partido. Sin embargo, Horacio siempre permanecerá en nuestros corazones frikis por el hecho de habernos otorgado tantos cientos de horas de diversión digital.
El tercero de los títulos, de 1983, era ‘Horace & the spiders‘ (‘Horacio y las arañas’), en el que nuestro amigo debía enfrentarse, a lo largo de tres fases, a unas terribles arañas carnívoras, saltando, balanceándose entre lianas y creando agujeros trampa para que los arácnidos cayeran en ellos. Para no perder la costumbre del plagio o copia, el tercer nivel de este tercer juego recuerda poderosamente al estilo de juego de ‘Lode Runner‘, un arcade de plataformas también de 1983.
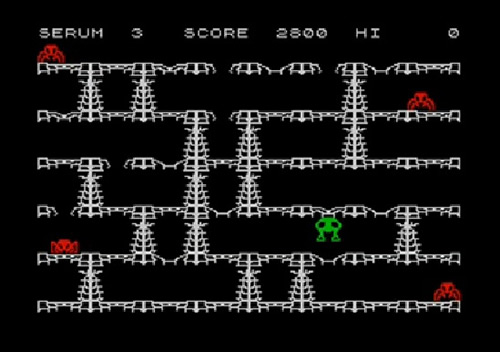
Pantalla de ‘Horace & the spiders’
La trilogía original estuvo apunto de convertirse en una saga de cuatro en 1985, cuando fue anunciada una secuela que se llamaría ‘Horace to the rescue‘ (‘Horacio al rescate’). Sin embargo, este juego nunca llegó a ver la luz. Decían los chismorreos de la época que William Tang estaba muy delicado de salud y no pudo proseguir su trabajo, aunque esto nunca ha sido confirmado.
Diez años después, en 1995, los fans de Horacio recibieron un sorpresón cuando Michael Ware, de la compañía de desarrollo británica Proteus Developments, programó una cuarta entrega titulada ‘Horace in the Mystic Woods‘ originalmente para las PDA Psion Series 3. Era un juego de plataformas muy similar (igual) al clásico ‘Manic Miner‘, por aquello de continuar con el estilo de imitación de otros juegos de la época. Sería 15 años después, en 2010, cuando el programador independiente Bob Smith codificara este último título para ZX Spectrum, convirtiéndolo ya en un clásico por sí mismo de emuladores y máquinas físicas de 8 bits.
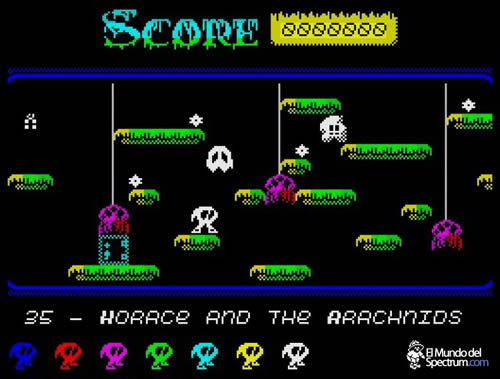
Pantalla de ‘Horace in the Mystic Woods’
Nuestro Horacio ha realizado posteriores cameos en videojuegos de diversa índole. El más cercano es del año 2003, en el que apareció en el juego ‘Dog’s Life’ para PlayStation 2 como parte de un cartel de una tienda llamada Horace’s Ski Shop. Y es que Horacio es mucho Horacio. Nos retrotrae a aquellos dulces años del software ochobitero, cuando esperábamos ansiosos el momento de jugar mientras escuchábamos los estridentes sonidos de carga del Spectrum. Por cierto, ahora que digo esto, los dos primeros títulos de Horacio, el de la glotonería y el del experto esquiador, aparecieron también en formato ROM para la ZX Interface 2. Afortunados aquellos que no habían de esperar para cargar y cuyos oídos no debían soportar aquel sinvivir.

Cintas de Horacio

![]()
![]()
